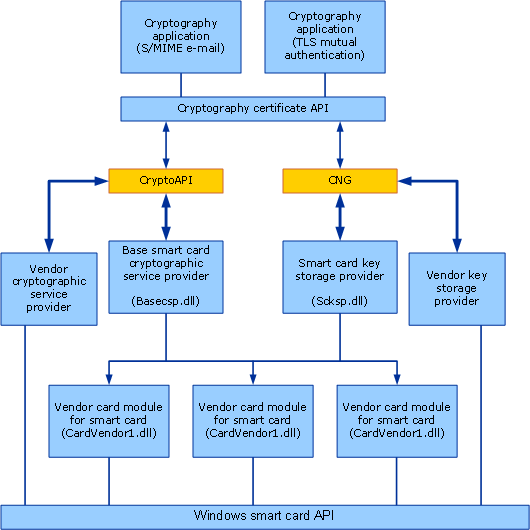
/etc/ssl/openssl.cnf添加以下配置
[openssl_init]
providers = provider_sect
# Load default TLS policy configuration
ssl_conf = ssl_module
alg_section = evp_properties
pkcs11 = pkcs11_section
[pkcs11_section]
engine_id = pkcs11
dynamic_path = /usr/lib64/engines-3/pkcs11.so
MODULE_PATH = /usr/lib64/opensc-pkcs11.so
init = 0
编译libp11
git clone https://github.com/OpenSC/libp11
cd libp11
autoreconf -fi
./configure --prefix=/usr
make && make install
ln -sf /usr/lib64/engines-3/libpkcs11.so /usr/lib64/libpkcs11.so
ubuntu上libp11叫libengine-pkcs11-openssl
执行openssl engine pkcs11 -t后显示以下内容就对了
(pkcs11) pkcs11 engine
[ available ]
但是我执行这个命令的时候70%的概率会报
/lib64/libpkcs11.so: undefined symbol: OPENSSL_finish
不过我用pkcs11生成证书时一直报错
openssl req -engine pkcs11 -new -keyform engine -key ‘pkcs11:model=PKCS%2315;manufacturer=EnterSafe;serial=2c692c97000a0025;token=OpenSC%20Card;id=%45;object=id_4’ -keyform engine -x509 -out cert.pem -text
Engine “pkcs11” set.
PKCS#11: Initializing the engine: (null)
Unable to load module (null)
PKCS11_get_private_key returned NULL
Could not find private key from org.openssl.engine:pkcs11:pkcs11:model=PKCS%2315;manufacturer=EnterSafe;serial=2c692c97000a0025;token=OpenSC%20Card;id=%45;object=id_4
00CE51640C7F0000:error:41000401:libp11:ERR_P11_error:Unable to load PKCS#11 module:p11_load.c:103:
00CE51640C7F0000:error:40800067:pkcs11 engine:ERR_ENG_error:invalid parameter:eng_back.c:730:
00CE51640C7F0000:error:13000080:engine routines:ENGINE_load_private_key:failed loading private key:crypto/engine/eng_pkey.c:79:
Views: 74