Views: 16
Views: 16
填充是PKCS#1的主要内容,占了正文三分之二的篇幅
早期的填充方式称为RSA-PKCS#1 v1.5填充,这种填充方式只是生成一个随机数与明文连接在一起,相对不安全,后来在RSA-PKCS#1 v2.1中(也就是RFC3447)定义了OAEP(用于加密)和PSS(用于签名)两种填充方式,新的填充方式使用MGF基于随机数对明文进行掩码处理。建议使用OAEP和PSS填充而不是RSA-PKCS#1 v1.5填充。
MGF: 掩码生成函数
https://datatracker.ietf.org/doc/rfc8017/
RSA-PKCS#1 v2.2
https://datatracker.ietf.org/doc/rfc3447/
RSA-PKCS#1 v2.1
Views: 108

SAE密钥交换示意图,PWE不是明文传输的,而是用u进行了掩码处理,就是mask_u,不过这个mask_u应该是直接参与运算而不需要去掩码的。
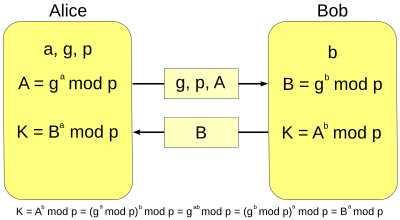
DH密钥交换示意图,其中g和p是公钥,A和B是公开的随机数,K是共享密钥
参考:
https://blog.csdn.net/weixin_47877869/article/details/136711988
Views: 27
PKCS#7(RFC2315)描述了Data(明文),Signed-data(签名), Enveloped-data(数字信封)signedAndEnvelopedData, digestedData, and encryptedData六种数据结构,并用PEM格式存储。定义了如何对数据进行签名和加密并进行存储的方法。在Windows上可以用PKCS#7来存储证书,它是通过无正文数据的Signed-data来存储证书的(后缀名为.p7b,事实上PKCS#7中data正文是必选的,证书是可选的),因为PKCS#7设计并不是专门用来存储证书的,这样存储蛮奇怪的而且不符合标准。
关于对证书的定义PKCS#12标准(RFC7292)的原话是:A digitally signed data unit binding a public key to identity information.
我的理解证书就是将身份信息用私钥进行签名,并把签名和公钥绑定在一起的数据单元(PKCS#12把存储的一个个数据对象称为PDU)。PKCS#7中的Signed-data包含了身份信息(虽然没有X.509中的身份信息详尽)和签名,但是没有包含公钥,所以不能称为证书。
PKCS#12定义了KeyBag,PKCS8ShroudedKeyBag,CertBag,CRLBag,SecretBag,SafeContents一共6种PDU类型和Data,EncryptedData,EnvelopedData三种PDU加密方式,但是仍然不包含公钥(虽然可以把证书文件塞进去作为CertBag)。PKCS#12是一个复合容器(keystore),可以存储多种不同类型的密钥和证书,并且可以对PDU进行加密和完整性验证。属于一种keystore,PKCS#12不用来存储用户数据。
按照PKCS#12和PKCS#8中的要求虽然KeyBag,PKCS8ShroudedKeyBag只用来存储单个私钥,是不能包含公钥的(虽然私钥可以导出公钥)。
PKCS虽然涵盖了PKI的方方面面,但是唯独没有定义证书的格式,只有X.509同时包含了身份信息,公钥,签名三种信息,符合证书的定义。
以上,只有X.509证书的说法,没有PKCS格式证书的说法,X.509证书可以保存在PKCS#12证书容器中。X.509与PKCS的大多数规范并没有太大关系,反而PKCS#7中的Signed data可以使用X.509证书,只有PKCS#1中定义的公私钥存储格式和RSA加密/签名操作规范在X.509中有所体现。
https://lapo.it/asn1js/
asn.1解码器,可以解码PKCS和X.509编码的文件
Views: 44
802.11r defines a three-level key hierarcy
1. Pairwise Master Key R0(PMK-R0) : The first level key of the FT key hierarchy. This key is derived from master session key (MSK)
2. Pairwise Master key R1(PMK-R1) : The second level key of the FT key hierarchy.
3. Pairwise Transit Key (PTK) : The third-level key of the FT key hierarchy. The PTK is the final key used to encrypt 802.11 data frames.

PMK-R0属于属于第一层,PMK-R1属于第二层,PMK属于第三层,S0和S1是PMK-R0和PMK-R1在STA上的对应体现。
– 首次连接
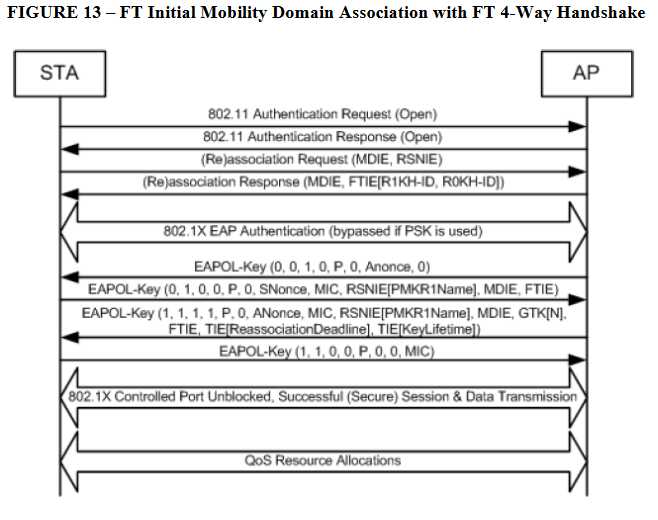
– Over-the-Air Fast BSS Transition
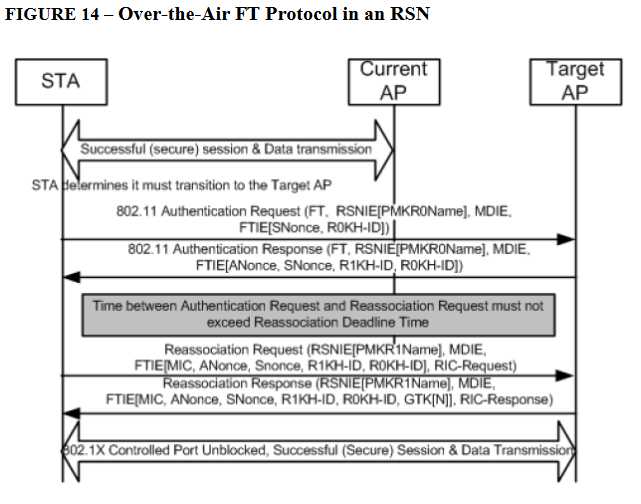
– Over-the-DS Fast BSS Transition
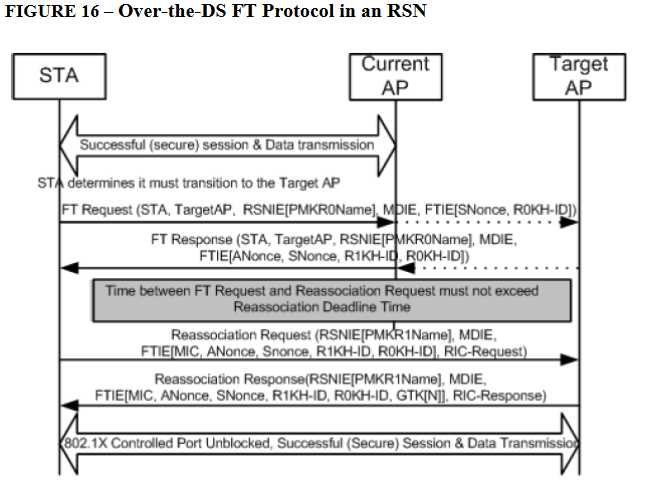
带Resource Request,多了一对握手包

参考:
https://www.cwnp.com/uploads/802-11_rsn_ft.pdf
Views: 31

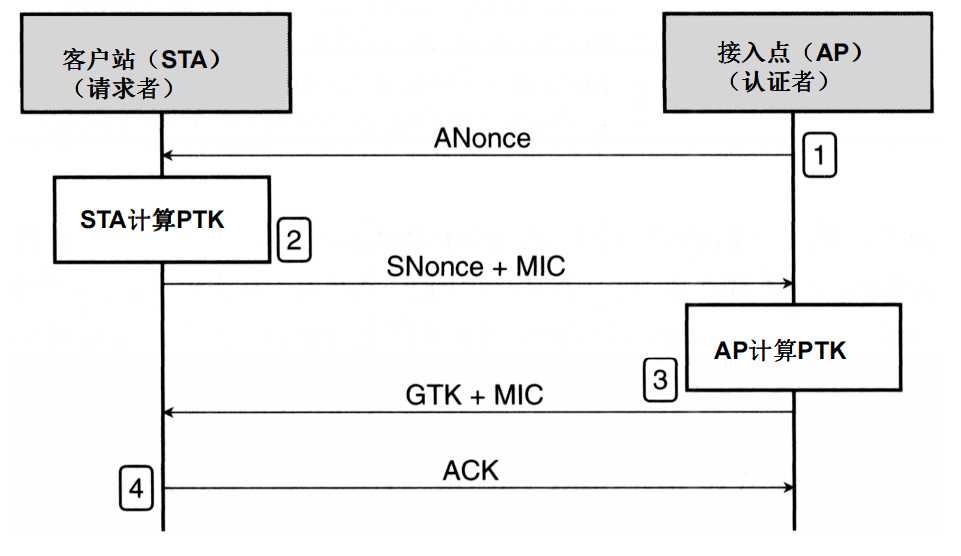

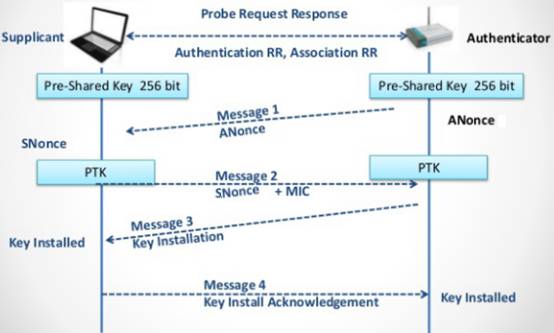
# Workaround for key reinstallation attacks
#
# This parameter can be used to disable retransmission of EAPOL-Key frames that
# are used to install keys (EAPOL-Key message 3/4 and group message 1/2). This
# is similar to setting wpa_group_update_count=1 and
# wpa_pairwise_update_count=1, but with no impact to message 1/4 and with
# extended timeout on the response to avoid causing issues with stations that
# may use aggressive power saving have very long time in replying to the
# EAPOL-Key messages.
#
# This option can be used to work around key reinstallation attacks on the
# station (supplicant) side in cases those station devices cannot be updated
# for some reason. By removing the retransmissions the attacker cannot cause
# key reinstallation with a delayed frame transmission. This is related to the
# station side vulnerabilities CVE-2017-13077, CVE-2017-13078, CVE-2017-13079,
# CVE-2017-13080, and CVE-2017-13081.
#
# This workaround might cause interoperability issues and reduced robustness of
# key negotiation especially in environments with heavy traffic load due to the
# number of attempts to perform the key exchange is reduced significantly. As
# such, this workaround is disabled by default (unless overridden in build
# configuration). To enable this, set the parameter to 1.
#wpa_disable_eapol_key_retries=1

Views: 62
AKM英文是Authentication and Key Management,在WPA中指的是认证和密钥交换及各种子密钥派生方法。
WPA3中的AKM主要分为企业模式,个人模式,Only模式,过渡模式。
SAE就是普通的WPA3-SAE模式,WPA3-Personal用的就是这个模式,SAE又分为SAE,SAE-GDH
SAE用的是Hunting and Pecking算法把PSK映射到ECC上的点,这种算法已被证明存在安全隐患,所以后面又推出了H2E算法,H2E就是Hash to Element,也就是Hash算法。
Hunting and Pecking的AKM编码是AKM8,Hash to Element的AKM编码是AKM24。6GHz频段要求仅支持AKM24。
也以客户端提供对H2E的支持:
– Android 12+
– Linux wpa_supplicant v2.10+ (see sae_pwe parameter for configuration)
– macOS Catalina+
– Windows 10 21H2+
下图是一部分AKM套件的编号

基于非对称密钥的SAE,先生成一个P-256的密钥对,然后算出来一个M值,M值参与生成签名,加入M值可以让签名的前sec个字节为0(抗第二原像攻击,防止找出第2个与指纹密码相同的公钥)。然后对公钥进行Hash运行,取前12位(最少12位,长度可以是4的倍数)作为wifi密码。在SAE握手的时候AP会把M值,随机数,Mac地址等一起进行签名,生成一个签名指纹。
AP会把公钥,签名,KEK加密的M值一起发送给STA,STA用密码对公钥进行验证,如果验证通过再用公钥验签(用于生成签名的输入是双方共享的),验签通过就是合法的AP。
这里不直接用公钥作为密码应该是因为公钥太长了,所以才对公钥进行Hash作为密码。
SAE-PK密码是这样的:
wsie-tyg2-x2rl-qsfs
wsie-tyg2-x2rl-qsfl-y2mr
wsie-tyg2-x2rl-qsfl-y2mc-t5yi
wsie-tyg2-x2rl-qsfl-y2mc-t5ye-rvc6
wsie-tyg2-x2rl-qsfl-y2mc-t5ye-rvcg-tr6e
wsie-tyg2-x2rl-qsfl-y2mc-t5ye-rvcg-tr65-5dhj
wsie-tyg2-x2rl-qsfl-y2mc-t5ye-rvcg-tr65-5dhu-touh
wsie-tyg2-x2rl-qsfl-y2mc-t5ye-rvcg-tr65-5dhu-touh-4sdz
wsie-tyg2-x2rl-qsfl-y2mc-t5ye-rvcg-tr65-5dhu-touh-4sdl-2mpz
SAE-PK密码同时作为普通的SAE密码使用,这样如果STA不支持SAE-PK则按普通SAE验证。也可以使用SAE-PK Only模式以抵抗降级攻击。
这个表是不同的凭据参数抗第二原像攻击的强度
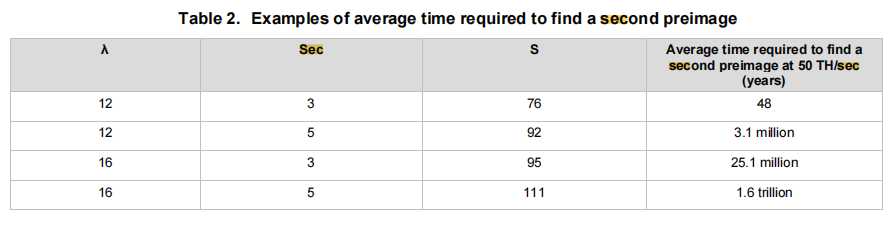
其中A是密码长度,Sec是Hash安全参数长度,S是破解所需计算量的数量级。Nvidia最新的GB200算力平台算力是720 PH/sec,破解76数量级的Hash只需要十几天。虽然Sec越长安全性越高,但是找到合适M值 的难度也更高。
如果STA已经信任AP的公钥(已经验证过或通过扫描识别),则不存在第二原像攻击。
Views: 161
在Wi-Fi中,WEP(Wired Equivalent Privacy)是一种早期的加密协议,用于保护无线网络通信的安全性。WEP的含义是提供与有线网络相当的安全性,1997年随第一代802.11协议推出。
WEP使用RC4加密,可以提供无线流量的加密,认证,完整性保护。
WEBP的密码是直接当密钥用的,不会做PRF处理。
目前常用的wep加密长度有:
1. 64-bit WEP: 其中密码长度为40位,也就是(40/8=)5个ASCII码。
2. 128-bit WEP:其中密码长度为104位,也就是(104/8=)13个ASCII码。
剩下的24bit就是IV(初始化向量),IV+Shared Key就是RC4的密钥。
802.11并没有规定IV的生成方式,只是规定IV不能重复,所以最好的方法无非是序列号。
WEP加密下的帧格式包括以下几个部分:
+------------------+------------------+------------------+------------------+
| MAC Header | IV | Encrypted Data | ICV |
+------------------+------------------+------------------+------------------+
以下是一个WEP加密帧的示例:
+------------------+------------------+------------------+------------------+
| MAC Header | IV | Encrypted Data | ICV |
+------------------+------------------+------------------+------------------+
| Frame Control | IV (3 bytes) | Encrypted Data | ICV (4 bytes) |
| Duration/ID | Key ID (1 byte) | (variable length)| |
| Address 1 | | | |
| Address 2 | | | |
| Address 3 | | | |
| Sequence Control | | | |
| Address 4 (opt.) | | | |
+------------------+------------------+------------------+------------------+
WEP加密下的Wi-Fi帧格式包括MAC Header、IV、加密数据和ICV。IV用于加密过程中的随机化,ICV用于验证数据的完整性。WEP使用RC4算法进行加密,但由于其安全性较弱,已经被更安全的协议(如WPA和WPA2)所取代。
WEP的主要问题是密钥不变而且无法防重放攻击,这样通过重放攻击制造大量报文,然后收集到足够的报文后再利用RC4的弱点就可以破解了。
Views: 116
中文叫挑战/应答或质询/应答,是一种身份认证方式,具体流程为:
1. 客户向认证服务器发出请求,要求进行身份认证;
3. 认证服务器内部产生一个随机数,作为”质询值”,发送给客户;
4. 客户把质询值用预先配置的密码进行RC4加密作为应答;
5. 认证服务器将应答串与自己的计算结果比较,若二者相同,则通过一次认证;否则,认证失败;
6. 认证服务器通知客户认证成功或失败。
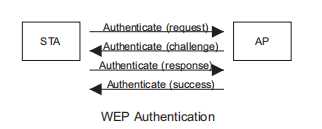
因为质询值是明文发送的,所以存在安全隐患。
Views: 40
因为使用同一个密码多次加密报文会降低加密数据的安全性,所以每个加密块都会使用唯一的密码加密。通常做法是用一个随机数或序列号或时间戳与密钥进行混合生成子密钥来加密数据。
如初始化向量是按特定规则生成的也可以称为nonce。
实际上复杂一点的情况初始化向量是由随机数和序列号,时间戳等共同组成的,可以是从左到右串起来,也可以是经过一定的运算。初始化向量中的随机数称为salt,比如AES-GCM中通常是4字节的Salt再加8字节的序列号。
根据TLS和IPsec中的定义初始化向量一般是12个字节组成,前4个是固定的salt,后8个是序列号。
在IPsec中Salt是在SA协商时生成的,在一个SA中不会改变,在TLS中Salt是在会话协商时生成的,在一个会话中不会改变。
因为解密的时候也需要IV,所以在不可靠连接(IPSec,DTLS,Wireguard,Wifi的WEP和WPA)加密时,IV都要附在密文前面一起发给对方。因为salt通常是固定的也可以也可以不在报文中发送,虽然序列号是可预测的,但是为了防止丢包(丢包后序列号就对不上了),在不可靠连接报文中发送IV仍然是必须的。
为了避免IV回绕可以执行密钥更新协议定时更新密钥。
以上只是一般做法,不同的算法和应用中IV的长度,生成方法,发送方式都会不同。
Views: 79