nextcloud自动删除过期文件
- 安装插件
Retention 根据条件(比如标签)删除文件
Files automated tagging 根据条件给文件打标签 - 设置标签
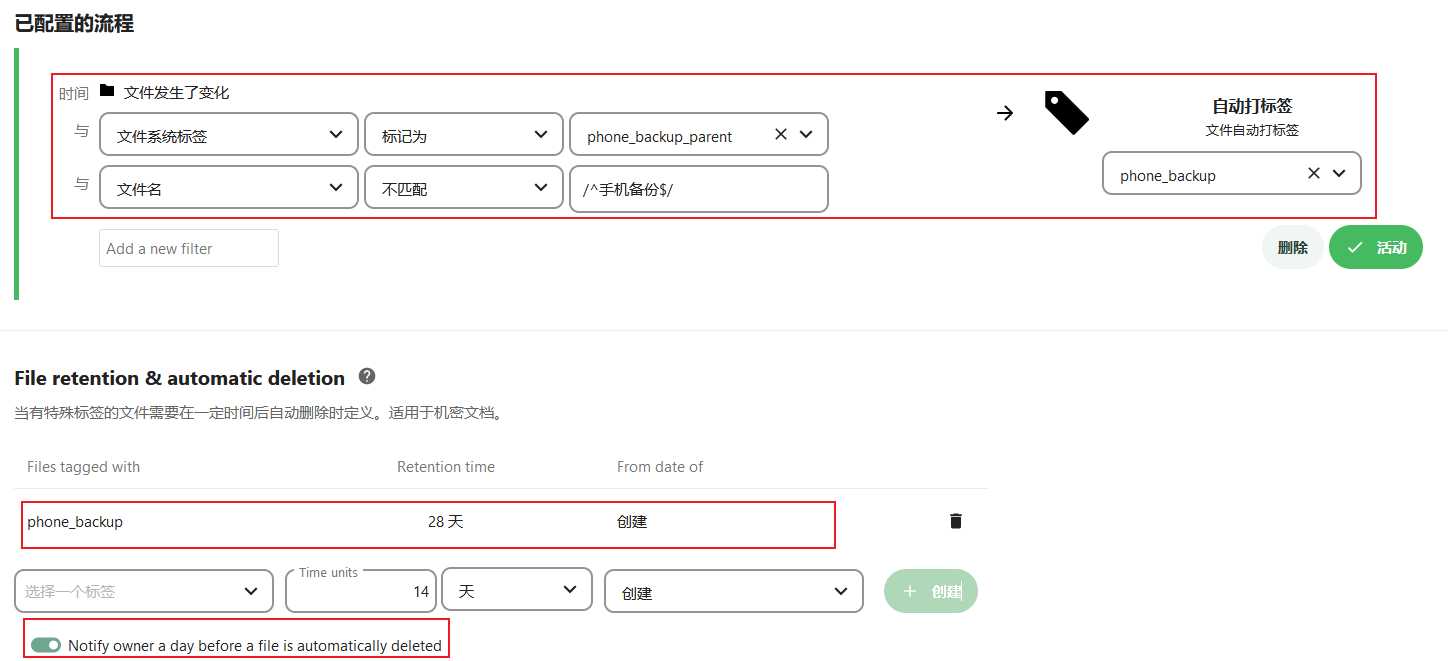
– 手动给要删除文件或文件夹的父目录设置标签,比如给目录手机备份添加标签”phone_backup_parent”
– 点击”管理设置”->”流程”
添加一个自动打标签流程,配置如下:
|条件类型|比较符|值|
|--------|------|-----|
|文件系统标签|标记为|phone_backup_parent|
|文件名|不匹配|/^手机备份$/|
然后动作选择"自动打标签",标签名为“phone_backup”
- 添加retention插件规则
还是在”管理设置”->”流程”页面
找到File retention & automatic deletion
标签选择”phone_backup”,时间选择”14天”,日期来源选择”创建”
然后点创建就添加了一条文件删除规则
配置截图
Views: 81