- Tahoe
这是最古老经典的拥塞算法,也就是常说的慢启动/拥塞避免机制。Tahoe的速率波动曲线如下:
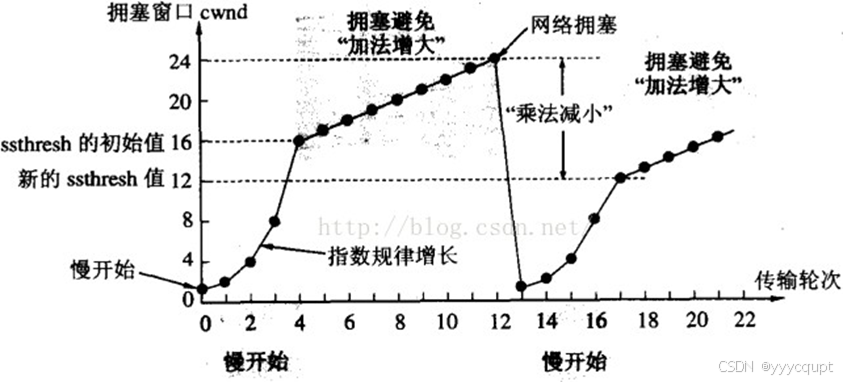 ssthresh是慢启动到拥塞避免的临界值,始终是上一次发生拥塞时窗口的一半,Tahoe在第一次拥塞避免结束后会直接把拥塞窗口降到1MSS,然后重新执行慢启动和拥塞避免。
ssthresh是慢启动到拥塞避免的临界值,始终是上一次发生拥塞时窗口的一半,Tahoe在第一次拥塞避免结束后会直接把拥塞窗口降到1MSS,然后重新执行慢启动和拥塞避免。
- Reno
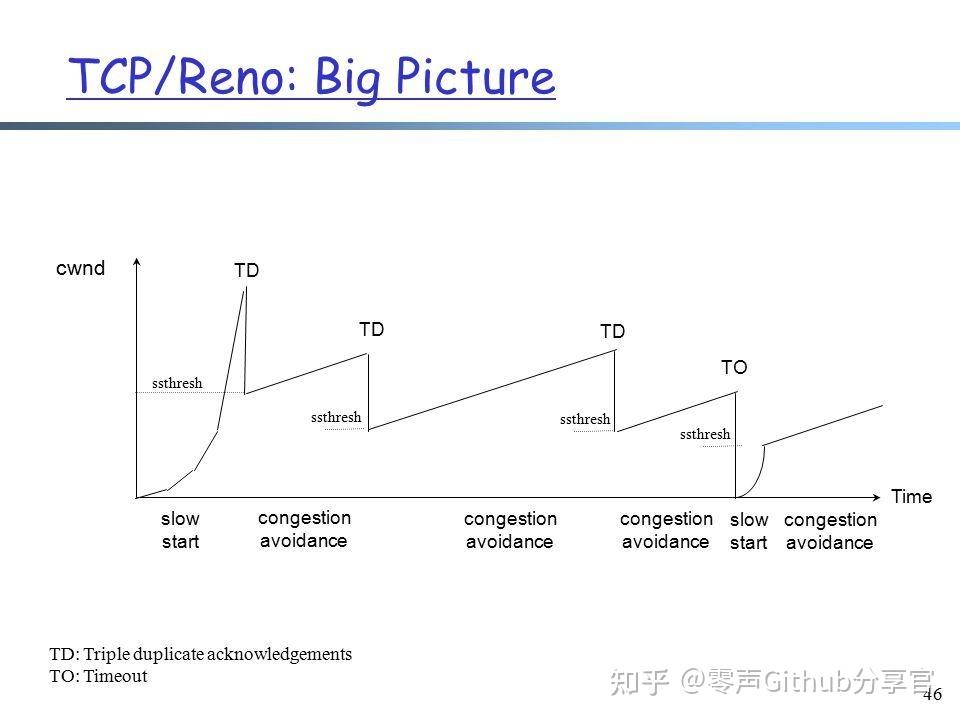
相对Tahoe算法Reno算法在发生快速重传后进入恢速恢复状态而不是慢启动状态,这样带宽惩罚更小。当然发生RTO(超时重传)后还是会进入慢启动状态。
- BIC
BIC的全称是Binary Increase Congestion,通过二分查找更快的找到最快速度。
- Cubic
CUBIC使用三次方函数提高拥塞避免阶段速率提升速度(其实是现慢后快),同时解决了RTT公平性问题。 传统的拥塞避免算法(Reno)基于RTT周期来增加发送速率,RTT越小的连接速度启动越快,这样对高延迟连接就很不公平,CUBIC的拥寒避免不再与RTT挂钩而是与固定时间挂钩。 在快速恢复状态下速减少到原来的70%而不是50%。 BIC和Cubic的慢启动和Reno都是一样的,都是倍增方式,区别主要是拥塞避免阶段,Cubic相比BIC速率波动更平缓,解决了RTT公平性问题。
- BBR
BBR会周期性的探测当前的实际延迟(RTprop)和带宽(BtlBw),RTprop和BtlBw是BBR引入的两个术语,表示当前网络的物理延迟和带宽。BBR会周期性的提高发送速率(25%)来探测BtlBw有没有增加,降低发送速率(inflight = 4,未确认包为4)来探测RTprop有没有减少。使用RTprop剩以BtlBw得到BDP(带宽延迟积),BDP表示正在飞行中(在传输管道中)的数据量,也即是未确认的数据量。当inflight大于BDP时cwnd会变满,会停止发送数据。
现代网络设备都有很大的队列缓存,当发生拥塞时数据会排队,然后就会引起延迟增加,不利于延迟敏感应用,使用BBR算法可以避免拥塞时产生的延迟增加或网络中断。
BBR算法probeBw周期是8个RTT,在稳定状态始终执行probeBw,这8个RTT周期对应的pacing_gain系数分别是1.25,0.75,1,1,1,1,1(probeBw就是通过控制pacing_gain来执行的),即1个RTT加速,1个RTT减速,剩余4个RTT匀速发送。(这个周期是参考网上别人的笔记和deepseek(怀疑deepseek也是网上抄来的),具体是不是这样还要结合源代码和IETF文档来验证) 但是probeRTT是每10s执行一次(固为RTTprop变化频率低,且测量RTTprop会影响带宽)。 BBRv1已经合并linux主线分支,但BBRv3尚没有合并(截止linux 6.15 RC5),v2应该只是实验版本不会对外发布,v3包含v2的功能。BBRv3修复了诸多bug,降低了重传序和延迟,与Cubic更好的共存,支持ECN等。
- GCC
GCC是WebRTC中默认的拥塞控制算法,可以同时基于丢包和延迟进行拥塞控制,相比BBR算法传输速率更稳定,延迟更低,抗丢包能力强,丢包率50%时仍能使用,但带宽利用率不如BBR。
TCP拥塞控制算法多如牛毛,以上是主要的几个算法。CUBIC算法可能存在的一个问题是bufferbloat。
Views: 54