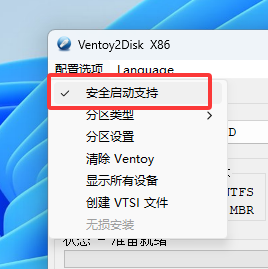
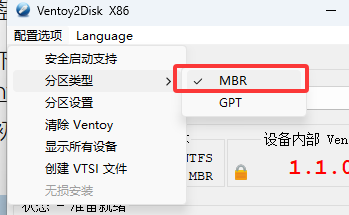
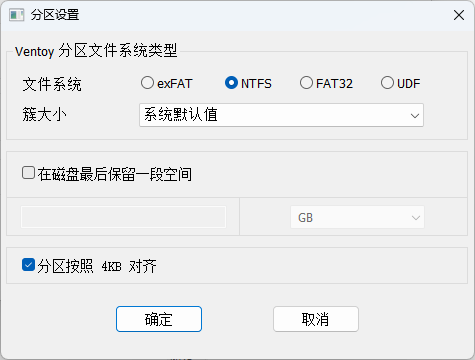
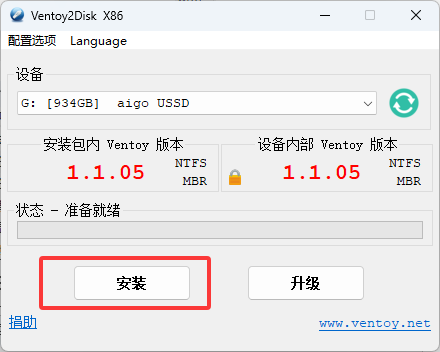
- 在/app/powerdnsadmin/lib/setting.py文件中编辑以下内容
# Zone Record Settings
'forward_records_allow_edit': {
'A': True,
'AAAA': True,
'AFSDB': False,
'ALIAS': False,
'CAA': True,
'CERT': False,
'CDNSKEY': False,
'CDS': False,
'CNAME': True,
'DNSKEY': False,
'DNAME': False,
'DS': False,
'HINFO': False,
'KEY': False,
'LOC': True,
'LUA': False,
'MX': True,
'NAPTR': False,
'NS': True,
'NSEC': False,
'NSEC3': False,
'NSEC3PARAM': False,
'OPENPGPKEY': False,
'PTR': True,
'RP': False,
'RRSIG': False,
'SOA': False,
'SPF': True,
'SSHFP': False,
'SRV': True,
'TKEY': False,
'TSIG': False,
'TLSA': False,
'SMIMEA': False,
'TXT': True,
'URI': False,
'HTTPS': True,
'SVCB': True
},
'reverse_records_allow_edit': {
'A': False,
'AAAA': False,
'AFSDB': False,
'ALIAS': False,
'CAA': False,
'CERT': False,
'CDNSKEY': False,
'CDS': False,
'CNAME': False,
'DNSKEY': False,
'DNAME': False,
'DS': False,
'HINFO': False,
'KEY': False,
'LOC': True,
'LUA': False,
'MX': False,
'NAPTR': False,
'NS': True,
'NSEC': False,
'NSEC3': False,
'NSEC3PARAM': False,
'OPENPGPKEY': False,
'PTR': True,
'RP': False,
'RRSIG': False,
'SOA': False,
'SPF': False,
'SSHFP': False,
'SRV': False,
'TKEY': False,
'TSIG': False,
'TLSA': False,
'SMIMEA': False,
'TXT': True,
'URI': False,
'HTTPS': False,
'SVCB': False
},
}2. 重启PowerDNS-Admin
docker compose restart admin
3. 配置PowerDNS-Admin
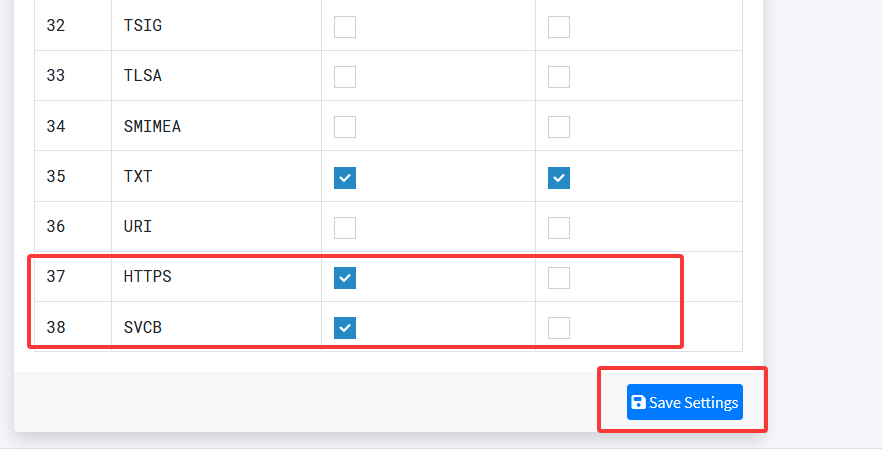
然后就可以添加HTTPS记录了
Views: 5
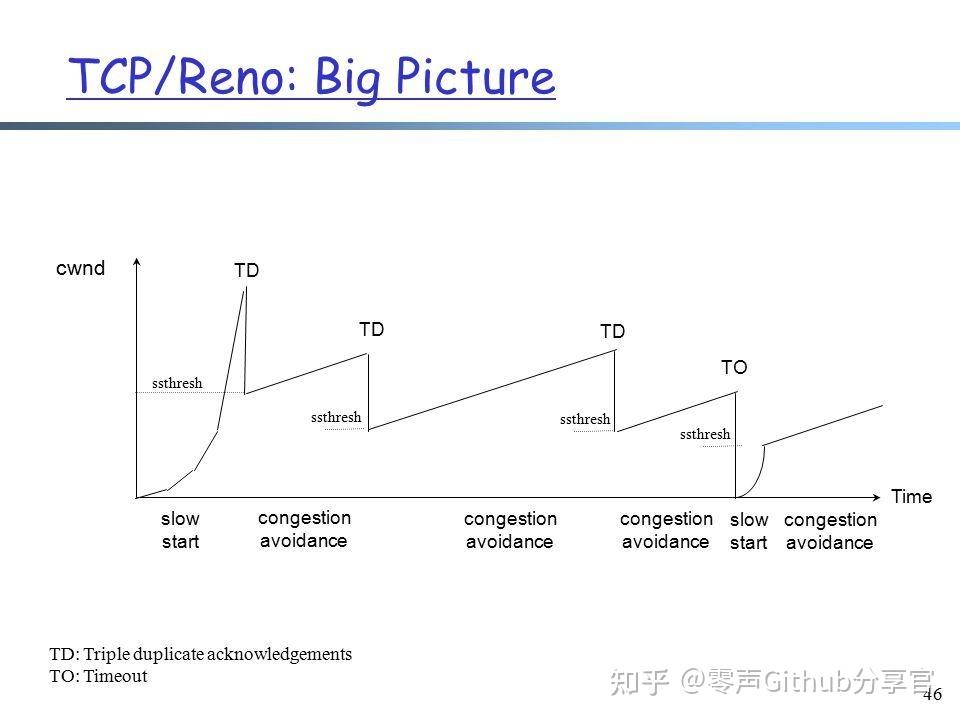
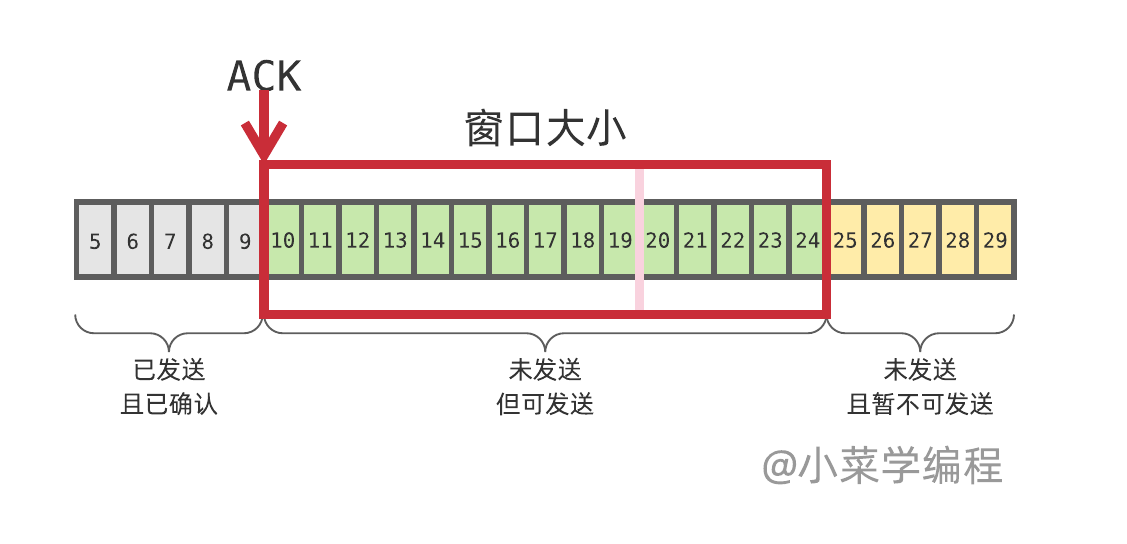
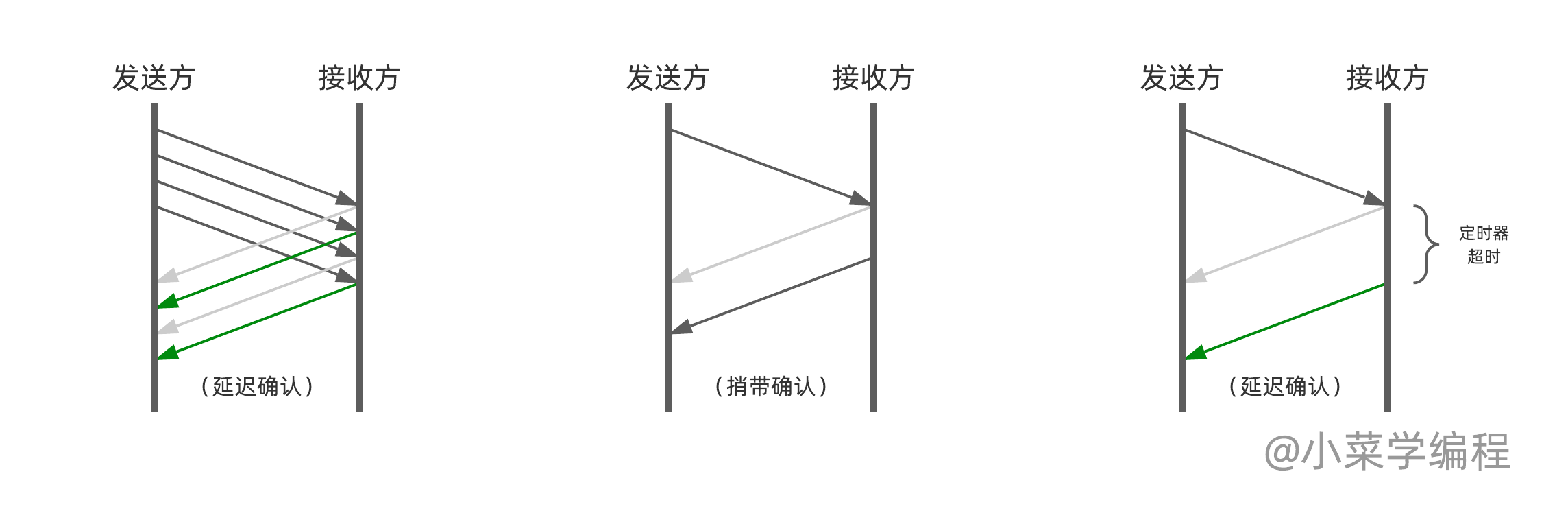
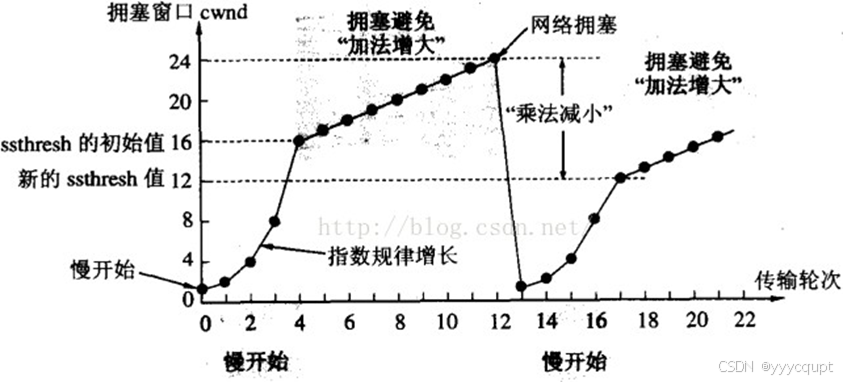 ssthresh是慢启动到拥塞避免的临界值,始终是上一次发生拥塞时窗口的一半,Tahoe在第一次拥塞避免结束后会直接把拥塞窗口降到1MSS,然后重新执行慢启动和拥塞避免。
ssthresh是慢启动到拥塞避免的临界值,始终是上一次发生拥塞时窗口的一半,Tahoe在第一次拥塞避免结束后会直接把拥塞窗口降到1MSS,然后重新执行慢启动和拥塞避免。